

tldr; Kitaru (来る, Japanese for “to arrive.”) is now open source and free for everyone. It offers robust, durable execution for async Python agents on any infrastructure backend. Kitaru is built on top of ZenML, leveraging five years of experience developing one of the world’s top open source MLOps workflow orchestration tools.
Here’s why we built it and what it does.
Agents have truly arrived
I spent a lot of the last 3 years talking to teams building agents. Not demos, actual production systems. These deployments created actual business value.
But it feels like since the beginning of this year, something has truly clicked.
OpenClaw became the fastest growing open-source project in history. Karpathy’s autoresearch runs 100 ML experiments while you sleep without you touching a thing.
The METR task-completion time horizon clearly showcases where the puck is going:
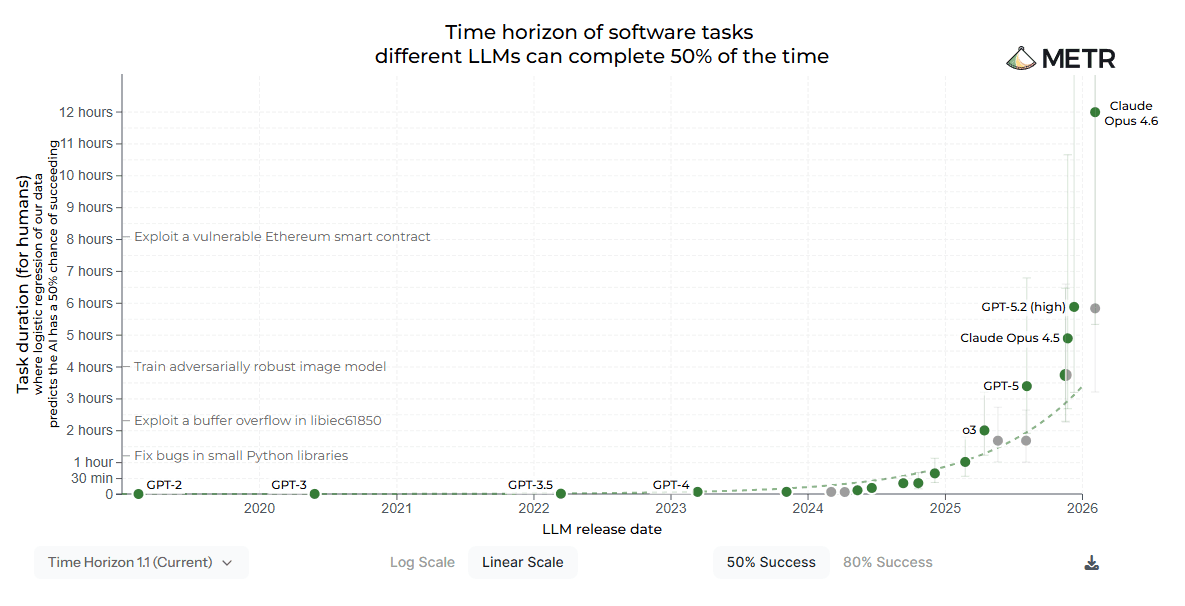
Agents doing long-horizon, deep work in the background, while you’re in a meeting, having coffee, or asleep, is where every serious engineering team is heading.
At the same time, there has been a collective realization that most good general agents are fundamentally coding agents. Anthropic discovered this last year when they found their coding harness generalizes well to general-purpose tasks, which led to the creation of Claude Cowork.
Coding allows you to express complex tasks on the shoulders of decades of software engineering practices that were built to solve such tasks. It is no wonder that it generalizes. Software is built to solve complex tasks, mostly in the workplace.
The opportunity cost is higher than it has ever been
Just in the last weeks, I’ve spoken to people experiencing “token anxiety”. I’ll be honest, I have a little myself. Running multiple coding agents in parallel, powered by sub-agent delegation, is the norm for me and the team.
It just feels like a chance wasted if your laptop is shut down and not working overnight: The opportunity cost of not running the next experiment is higher than it used to be.
I believe that having an army of agents running autonomously in the background and coordinating complex value-creation tasks will quickly become a norm worldwide.
Which leads me to a seemingly obvious prediction:
These agents need to move out of our local machines
These agents work. But today, most of them are trapped in individual local machines.
They shutdown when your machine does. They cannot talk to coordinate with other agents doing other types of work. They are fragile and their results are hard to reproduce.
This is a natural start - and there is a lot of value in a category of agents that will never leave their host machines. One can point to the continuous sales of Mac Minis as a proxy to understand this.
However, there is a natural incentive for most enterprises to invest in building infrastructure that allows these agents to break free of their hosts, and join a managed army working together autonomously and without human intervention (for the most part). Spotify’s Honk is an early example: a background coding agent that has merged over 650 pull requests a month autonomously.
Digging deeper, this is fundamentally a platform problem. While the model providers are naturally inclined to eat that part of the stack, if past history is any indicator, a big portion of the market would do well to invest in building internal platforms to deploy and run these agents themselves - on their terms.
It is now clear that companies that will succeed with agents are the ones who have in-house knowledge on how to develop, deploy, and manage ambient agents at scale.
That’s where Kitaru comes in.
What Kitaru is
Kitaru allows long-horizon ambient agents to leave their host and run on your company’s infrastructure / cloud provider.
We followed the following principles when designing Kitaru:
- Observability built-in. The dashboard ships free with the server. Not a paid add-on. Every run is visible: checkpoint by checkpoint, what each step produced, what each LLM call cost. When something breaks at step 6 you’re not reading logs. You’re looking at what step 3 actually returned and replaying from there.
- Deployment flexibility. No workers. No message queues. No distributed architecture to manage. Kitaru runs on a single server and a SQL database. Start local, and point it at Kubernetes, Vertex AI, SageMaker, or AzureML and it works.
- Python-first, no lock-in.
if,for,try/except: it all works. No graph DSL to learn. No framework opinions imposed on you. Kitaru wraps your code. It doesn’t care how you wrote it.
In 2026, there are many tools that claim to do similar things. With Kitaru, we want to make it easy to understand what we do well, and what we consider out of our purview.
First, Kitaru is not a tracing observability tool. In our view, the missing piece isn’t observability. Most teams already are tracking their traces. While extremely useful, the problem is that traces are passive. They tell you what happened after the fact, from a distance, in a dashboard that has nothing to do with your code. They don’t help your agent recover from where it failed. They don’t let you pause mid-run and get a human to approve before the expensive step. They don’t scale your execution out of your laptop and onto a real cloud environment.
What companies running agents at scale need on top of traces is execution that survives failures, control at the function level, human approval gates that actually pause the process, and the ability to run the same agent locally and in production without a rewrite.
Finally, Kitaru is not an agent framework. Agent frameworks give building blocks to design AI agents. Depending on your use-case, you might or might not need to use agent frameworks.
While the lines are still blurry, most frameworks stop at the boundary of taking over responsibility of deployment and management. For example, the awesome Pydantic AI framework gives an abstraction where tools like Kitaru can be plugged in to orchestrate and interface with the runtime. The OpenAI Agents SDK and CrewAI SDK have similar abstractions.
Kitaru ships with a Pydantic AI adapter at launch. We will develop more integrations soon. The goal is not to get in the way of your framework choice, but enable you to run and deploy agents at scale despite it.
Show me the code
After a pip install kitaru, start with:
import kitaru
from kitaru import flow, checkpoint
# `@checkpoint` persists each function's output so if the agent crashes at step 3, steps 1 and 2 never run again.
@checkpoint
def research(topic: str) -> str:
# `kitaru.llm()` resolves the model alias, injects the API key from secrets automatically,
# and logs the call (latency, token count, cost) against the enclosing checkpoint.
return kitaru.llm(f"Research this topic in depth: {topic}", model="fast")
@checkpoint
def write_draft(topic: str, notes: str) -> str:
return kitaru.llm(f"Write a blog post about {topic}:\n{notes}", model="fast")
@flow
def writing_agent(topic: str) -> str:
notes = research(topic)
draft = write_draft(topic, notes)
# Suspends the whole process, releases compute, and resumes when a human responds.
# 30 seconds or 3 days later, doesn't matter.
approved = kitaru.wait(
schema=bool,
question=f"Approve this draft?\n\n{draft[:500]}",
)
if not approved:
return "Draft rejected by reviewer."
return draftIf you’ve used ZenML, you know the stack abstraction. Kitaru uses the same idea. This is as simple as:
kitaru stack create prod-k8s \
--type kubernetes \
--artifact-store s3://my-bucket/kitaru \
--container-registry 123456789012.dkr.ecr.eu-west-1.amazonaws.com \
--cluster prod-cluster \
--region eu-west-1 \
--namespace ml
kitaru stack use prod-k8sAnd run the same code above, and now the code runs as K8s jobs that are orchestrated centrally via the Kitaru server. You have full control over this orchestration setup, and it works on all major cloud providers. This mechanism is also extensible.
What we’re still building
The core is solid. A few things we’re actively working toward:
Multi-agent coordination: agents calling subagents, tracking lineage across them, sharing context mid-run. The primitives exist, the polished end-to-end experience doesn’t yet.
Cross-run memory: agents that remember things across separate executions without you wiring up a vector database. We know exactly what we want to build here and it’s coming.
Aggregated cost dashboards: right now you see cost per run. Total spend across all your flows over time is next.
OpenTelemetry export: Kitaru already tracks every checkpoint and LLM call internally. Exporting that trace data to tools like Langfuse, Logfire, or any OTLP-compatible backend is coming soon, so you can pipe runs into whatever observability stack you already use.
More execution stacks: Kubernetes, Vertex AI, SageMaker, and AzureML are shipped. Vercel, Cloudflare Workers, and other serverless targets are next. The stack abstraction is designed for this; it’s mostly a matter of building and testing the adapters.
The repo is public. The roadmap is public. We’d rather ship real things than announce futures.
Five years of ZenML under the hood
We are not starting from zero. The artifact store, the metadata layer, the orchestration engine, the stack abstraction: that’s the same ZenML infrastructure that teams at JetBrains, Adeo, and the Bundeswehr have run in production for years.
We built ZenML because ML teams couldn’t reproduce their training pipelines or track what happened to their data. Then we watched the exact same problem show up for agents. Teams who couldn’t reproduce a failed run. Couldn’t see what their agent was doing. Couldn’t trust it in production.
Same problem. Different workload. This time we built the interface from scratch rather than bending a pipeline model into something it wasn’t designed for.
Getting started
pip install kitaru # or use uvAdd @flow and @checkpoint to your agent and run it. That’s the whole onboarding.
To connect to the dashboard:
kitaru login
# or point at your remote server: kitaru login --url https://your-server-urlThe stack commands shown above work identically against Kubernetes, AWS, GCP, and Azure: same agent code, different target. The getting started guide has the full walkthrough, and the coding agent example walks through a real production agent end to end. Eight stages, checkpointed throughout, with a human approval gate before the expensive work starts.
If your agents are dying in production and you’re tired of restarting from scratch, give it a try. Or simply give us a star on GitHub to show support!