Everything around the agent loop.
Deploy, track, and govern autonomous agents on your cloud. Any framework. Any model.
pip install kitaru  Watch the demo
Watch the demo The agent loop is solved. The platform around it isn't.
Agent SDKs solve the inner loop: tool calls, LLM calls, sandboxes. That's the easy part now.
Everything in the outer loop (how the agent is deployed, what state it remembers, how it's dispatched, how runs are tracked) gets rebuilt from scratch, company by company.

State your agents can come back to.
Versioned, scoped memory that persists across executions. Write it from Python, read it from the CLI or MCP. Agents remember conventions, context, and prior work across runs.

Dispatch from anywhere.
CLI, Python script, or HTTP. Define the agent once and call it from any entry point. Kitaru's runtime absorbs the differences so the same flow runs the same way.

Inspect every run.
Every execution is versioned, every checkpoint persisted, every artifact tracked. Open the dashboard and see exactly what happened. Built in, not bolted on.
One import. Any agent SDK.
Keep your agent, your sandbox, your manifest exactly as they are. Swap one import and get checkpointed execution, artifact tracking, and observability, without changing a line of your agent code.
from agents import Runner
from agents.sandbox import SandboxAgent, Manifest
agent = SandboxAgent(
name="Compliance Reviewer",
model="gpt-5.4",
default_manifest=manifest,
)
result = await Runner.run(agent, task)from kitaru.integrations.openai import KitaruRunner
from agents.sandbox import SandboxAgent, Manifest
agent = SandboxAgent(
name="Compliance Reviewer",
model="gpt-5.4",
default_manifest=manifest,
)
result = await KitaruRunner.run(agent, task)from claude_agent_sdk import query, ClaudeAgentOptions
options = ClaudeAgentOptions(
system_prompt="You are a compliance reviewer.",
allowed_tools=["search_docs", "fetch_policy"],
)
async for msg in query(prompt=task, options=options):
process(msg)from kitaru.integrations.claude import kitaru_query
from claude_agent_sdk import ClaudeAgentOptions
options = ClaudeAgentOptions(
system_prompt="You are a compliance reviewer.",
allowed_tools=["search_docs", "fetch_policy"],
)
async for msg in kitaru_query(prompt=task, options=options):
process(msg)from pydantic_ai import Agent
agent = Agent(
"openai:gpt-5.4",
system_prompt="You are a compliance reviewer.",
tools=[search_docs, fetch_policy],
)
result = await agent.run(task)from kitaru.integrations.pydanticai import kitaru_agent
from pydantic_ai import Agent
agent = kitaru_agent(Agent(
"openai:gpt-5.4",
system_prompt="You are a compliance reviewer.",
tools=[search_docs, fetch_policy],
))
result = await agent.run(task)from anthropic import Anthropic
client = Anthropic()
def my_agent(task: str) -> str:
plan = analyze(client, task)
# crash here? everything above is lost.
result = execute(client, plan)
return resultfrom kitaru import flow, checkpoint
from anthropic import Anthropic
client = Anthropic()
@flow
def my_agent(task: str) -> str:
plan = checkpoint(analyze)(client, task)
result = checkpoint(execute)(client, plan)
return resultCore primitives. Full durability.
import kitaru
from kitaru import flow, checkpoint
kitaru.configure(stack="kubernetes")
@checkpoint
def research(topic: str) -> dict:
results = search_web(topic)
kitaru.save("sources", results)
return summarize(results)
@checkpoint
def write_draft(context: str, prev_id: str) -> str:
prior = kitaru.load(prev_id, "sources")
return kitaru.llm(
"Draft a report on: " + context,
model="gpt-4o",
)
@flow
def report_agent(topic: str, prev_id: str) -> str:
data = research(topic)
draft = write_draft(str(data), prev_id)
kitaru.log(topic=topic, words=len(draft.split()))
approved = kitaru.wait(
schema=bool, question="Publish?"
)
if approved:
publish(draft)
return draft@flow Top-level orchestration boundary. Marks a function as a durable workflow.
@checkpoint Persists output. Crash at step 3? Steps 1-2 never re-run.
kitaru.wait() Suspends the process. Resume when a human responds, 30s or 3 days later.
kitaru.llm() Resolves the model alias and injects the API key.
kitaru.log() Structured metadata on every execution. Query it in the dashboard.
kitaru.save() Persist any artifact by name inside a checkpoint.
kitaru.load() Retrieve saved artifacts from any prior execution by ID.
kitaru.configure() Set stack, project, and runtime defaults. Zero config locally.
The primitives long-running agents keep needing.
These are the runtime basics teams keep rebuilding once agents leave the laptop.
Pause. Get input. Continue later.
Suspends at decision points, releases compute, and resumes when input arrives from a human, another agent, or a webhook, even hours or days later.
Crash at step 6? Resume from step 6.
Every step is checkpointed. Fix the issue and replay from the point of failure instead of re-burning tokens.
Keep your framework. Add durable execution.
OpenAI Agents SDK, Anthropic Agent SDK, PydanticAI, LangGraph, or raw Python. Wrap it with Kitaru and get checkpointed execution without rewriting your agent.
Fan out work without losing recovery.
checkpoint.submit() dispatches branches concurrently. Each keeps its own checkpoint history, so you can replay only the failed branch.
Your framework. Your model. Your sandbox.
Shipped, governed, observable.
Agent SDKs give you the loop. Sandboxes give you compute. Kitaru adds the layer in between (checkpoints, artifacts, replay, and memory) so your agent can run in production without rewriting it.
import kitaru
from kitaru import flow, checkpoint
@flow
def coding_agent(issue: str) -> str:
plan = analyze_issue(issue)
patch = write_code(plan)
# Pauses. Resumes when input arrives.
approved = kitaru.wait(
bool, question="Merge this PR?"
)
if approved:
merge(patch)
return patchFrom laptop to enterprise. Same OSS stack.
A CLI, a dashboard, and a scalable execution server. All open source. Runs on your laptop and scales to your cloud.
uv add kitaru && kitaru login 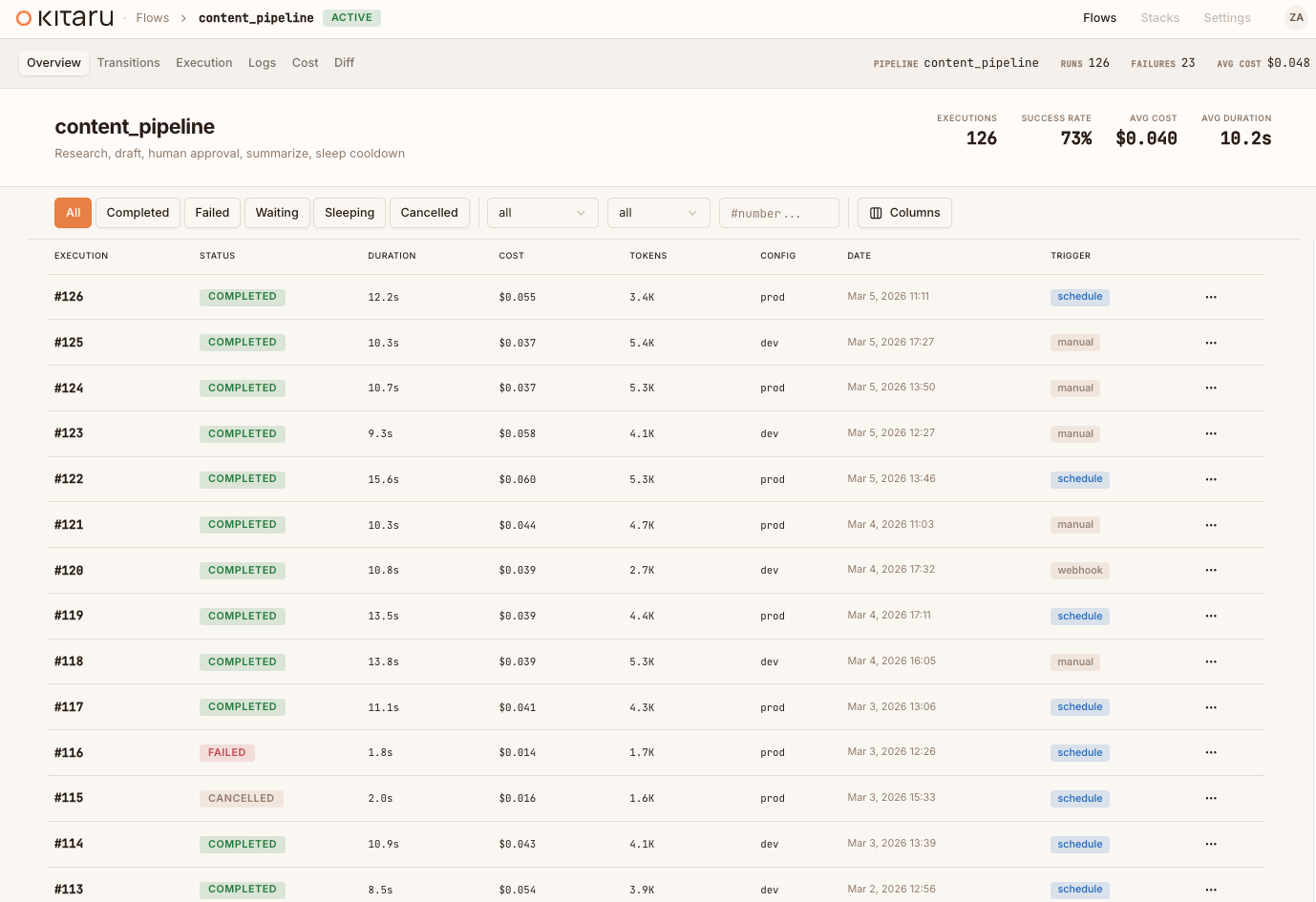
Your agent crashed at step 5.
Stop re-running steps 1 through 4.
pip install kitaru Open source (Apache 2.0). pip install and go.
Foundations and proof for Kitaru
Five years of production orchestration. Rebuilt for autonomous agents.
Kitaru is built by the team behind ZenML, trusted in production at JetBrains, Adeo, and Brevo. Now purpose-built for the lifecycle of autonomous AI agents: checkpoints, human-in-the-loop, deployment, and multi-team governance.
From ZenML to Kitaru
Why we rebuilt the orchestration primitives for autonomous agents, and what stayed the same.
Read post → ConceptWhy agents need durable execution
Crashes, timeouts, and human waits are routine. Without durability, every failure means starting over.
Read post → PerspectiveAgents need more than traces
Observability tools score runs. But lineage, versioning, and gates live at the infrastructure layer.
Read post →